
Good Boundaries Make Good Systems

No dogma, just what I'm learning and thinking about right now.
Comments and feedback are welcome on Mastodon.
"If you're thinking without writing, then you just think you're thinking."
—Leslie Lamport
This is the third of three articles discussing modularity patterns in Ruby.
-
What exactly are modules and how do we use them?
Recap
In the first article I argued that increasing complexity is inevitable in any system that models real-world problems. This complexity becomes embodied in our systems through the rapid growth of nodes–and the exponential proliferation of potential connections between nodes–as the system attempts to model larger portions of the real-world problem space. We saw that this proliferation also made it difficult to maintain shared mental models of the complete system among team members, hampering team growth.
We identified three criteria for a satisfactory solution to managing a growing real-world system:
-
Allow for the increasing complexity caused by real-world interactions.
-
Manage the proliferation of connections in a system destined to grow over time.
-
Cultivate sustainable shared mental models.
In the second article we looked at early strategies for dealing with this complexity, such as the “perfect information sharing” approach described by Fred Brooks in The Mythical Man-Month. We also learned that the concept of “modules” already existed in the projects Fred Brooks had described, but these modules amounted to little more than code organization structures.
We learned about David Parnas, who took a different approach to managing complexity. Parnas viewed the uncontrolled proliferation of connections between modules as the root cause of slowing progress. To remedy the problem, Parnas introduced the concepts of “information hiding” and “public interfaces” for modules. Implementing these ideas allowed modules to evolve from code organization tools to proper “boundary objects.”
When exploring systems based on the idea of modules-as-boundary-objects, Parnas found that those designed around boundaries looked very different from the compositions crafted by the top-down system designers of the day. We concluded with the conjecture that Parnas’ experiments revealed the most important principle of system design: module autonomy. Without autonomy driving module design, boundaries alone are insufficient to tame complexity.
In this article we will focus on the practical implications of taking autonomy as our guiding principle in modular system design. Do autonomous modules satisfy our solution criteria? As always when we deal with boundaries, what goes in and what goes out?
Ruby’s Sordid History of Promiscuous Boundaries
If you have a background in object-oriented programming (OOP), you may be thinking that information hiding and interfaces sound a lot like OOP’s central concept of encapsulation. I agree. To me, they are the same idea, but at different levels of application. Different altitudes, if you will. Since Ruby is an explicitly OOP language, you would think that modular system design would be a natural fit for Ruby, that it would be common and accepted. But it is not.
Strict boundaries like those required for autonomous modules seem to be anathema to Rubyists. Heck, even Sandi Metz has admitted to poaching private methods when she “needs to” (the link is timed for context; her confession is about a minute in). Why is this so? It is because OOP is not the first design principle of the Ruby language, developer happiness is. Boundaries just don’t seem to spark joy for Ruby developers.
Consider this series of posts from Brandon Weaver, a seasoned Ruby developer and frequent conference speaker, describing his experience with projects seeking to “modularize” existing Rails apps.
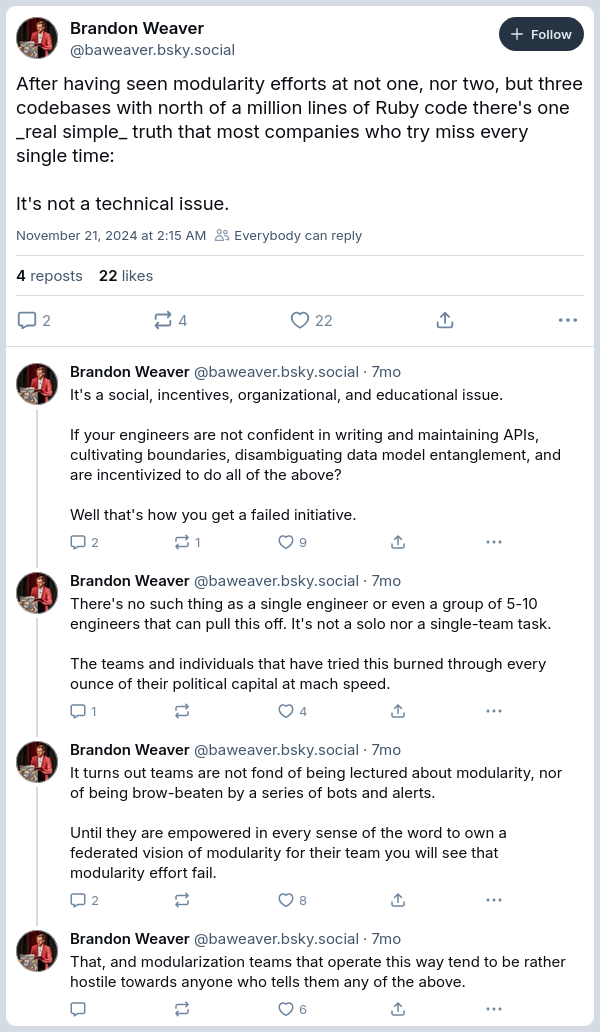
This is a serious problem. Clearly, any project that wishes to implement modules to manage complexity needs buy-in from the development team, and that buy-in requires clarity regarding the problem being addressed, the suitability of modularity as a solution, and good practices for designing autonomous modules. The goal of these articles is to seek that clarity.
So what are good practices for designing autonomous modules? I would like to discuss three of them here:
-
What’s in, what’s out?
-
Finding the seams.
-
Beware the monolithic database.
Along the way, we will look for some simple conventions that might support sound modularity practices. Let’s dig in.
What’s In, What’s Out?
This principle is about what belongs inside our modules and what doesn’t. I like to use the metaphor of “essence and accident” to help to understand this principle. This metaphor seems to be having a moment right now. I’m seeing it everywhere, so I think it’s useful to be as specific as I can with its usage before its meaning becomes muddy with overuse.
The dichotomy of essence versus accident originates with Greek philosophers, including Aristotle (see, e.g., Accident (philosophy)). I learned of it from Fred Brooks in his essay, “No Silver Bullet–Essence and Accident in Software Engineering,” included in The Mythical Man-Month, Anniversary Edition. Brooks, in turn, learned it from his wife, Nancy Lee Greenwood Brooks.
Brooks used this dichotomy to categorize the complexity in software systems. For Brooks, accidental complexity is the characteristics of software as software: manipulating registers, managing memory, handling inputs, sending outputs, etc. Brooks believed that accidental complexity could be reduced through tools like higher-level languages (he was very hopeful for object-oriented programming) that could abstract away these problems and allow developers to focus on essential complexity.
Conversely, essential complexity is the complexity of the problem the software is designed to solve–what we refer to as the domain. This complexity cannot be reduced, because it originates in the problem itself. Brooks concluded that since essential complexity cannot be avoided or compressed, unless accidental complexity represents the majority of the overall complexity of the system (greater than 90%), then there would be “no silver bullet” that would allow software development to increase in productivity over time in the way that so many other technologies seemed to advance–by orders of magnitude.
Expanding on Brooks’ usage, I propose our first convention: that modules should separate the essential complexity of the system from the accidental. The essential domain logic goes in, the accidental stuff–everything that is not domain logic–stays out. How do we recognize the difference? This can be tricky in Rails. Here is one approach that Sandi Metz described (jump to the 28:00 mark for this, but about 10 minutes earlier will give a lot of great context): she starts by opening the Models folder and making a new sub-folder, “AR.” Then she moves any class that inherits from ActiveRecord into the AR folder. The Model folder itself becomes the home for her domain logic–the essential complexity in her app.
If you are a fan of any of the Clean/Hexagonal/Onion/Ports-and-Adapters architectural patterns, I see all of them as similar schemes for separating accidental from essential complexity.
Aside: while the explanations around these patterns all tend to be frustratingly vague, I found the diagrams used by Robert Martin in his Architecture, the Lost Years talk to be the most informative.
I recently caught a talk by Alistair Cockburn on ports-and-adapters that was easily the most coherent explanation for this pattern that I’ve seen. The following diagram from his talk contains the biggest takeaway: the most important boundary in your application is the one around your domain logic. In this diagram, this is not the blue (outer) boundary, it is the purple (inner) boundary.
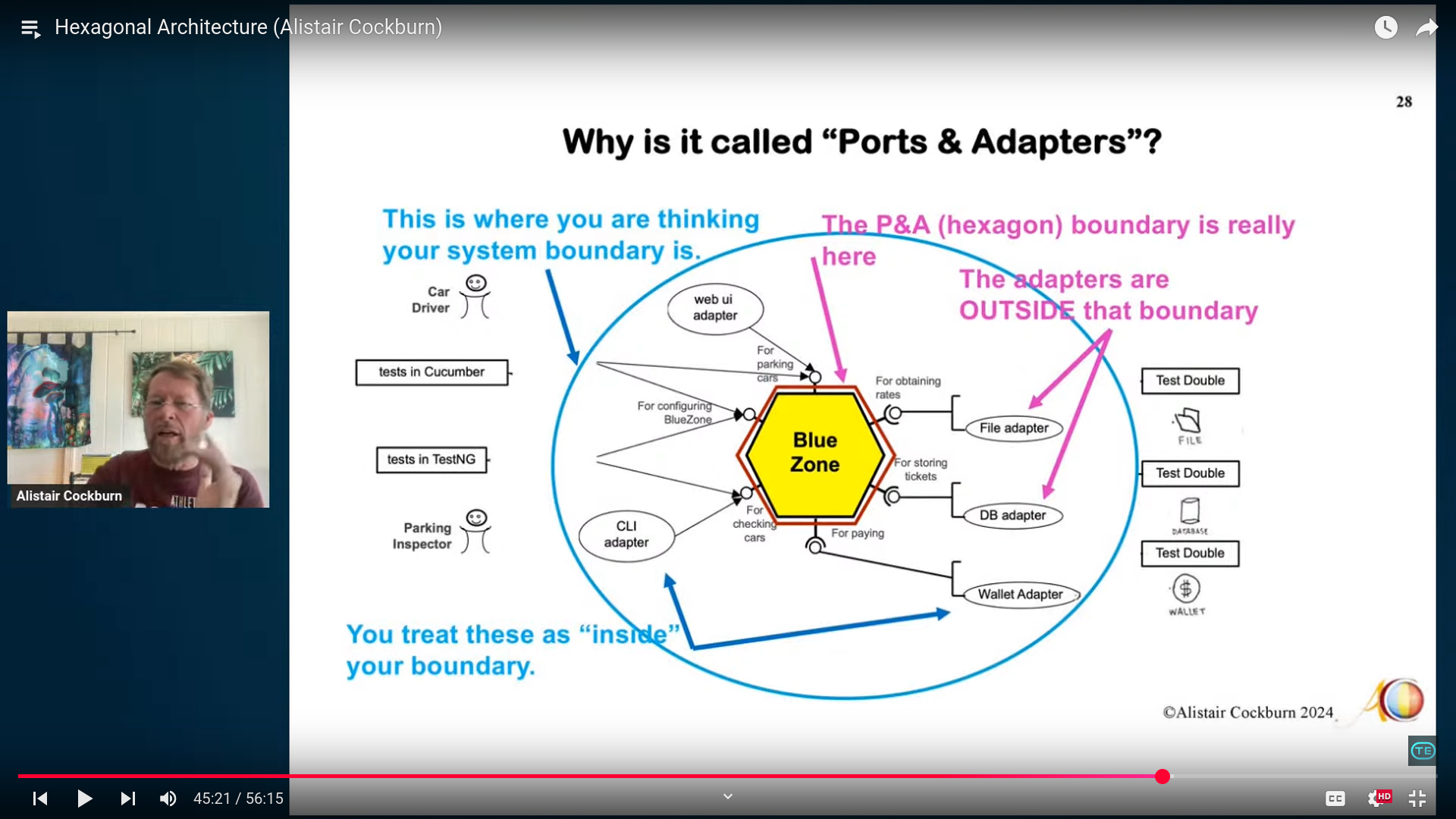
This bears repeating: if the Clean/Hexagonal/Onion patterns have any value, it lies in understanding that the boundary of your domain is the purple line (pink? mulberry? fuchsia? pale violet red? Gha! 🙄), not the blue one. What does this mean for Rails developers?
In Model-View-Controller terms, controllers and views are part of the user interface (UI) layer, outside of the domain logic. They are accidental complexity–accidental to the fact that Rails apps are web apps. The same is true for jobs, mailers, mailboxes, channels, etc. In Alistair Cockburn’s definition, they are all adapters. As such, they should be devoid of domain logic.
If you constrain yourself to “MVC” (that is, no other abstractions are permitted), then models are the home for your domain logic–not because they incorporate persistence (this is tangential and not ideal), but by process of elimination. Thus, Metz’s tactic of moving ActiveRecord objects to their own folder now makes sense: she is making room in the Models folder for her domain logic. ActiveRecord objects, reduced mainly to their persistence role, are dependencies of the domain logic. Conceptually (although not strictly in her practice), they also lie outside of the domain logic.
But what about service objects? I see service objects and other similar approaches as alternative implementations of Metz’s practice: a place for domain logic outside of ActiveRecord objects. More than likely, these “service” layers or other layers in your Rails app also represent essential complexity (domain logic) and belong in modules.
Returning to our theme, how does the convention of separating accidental and essential complexity advance our goal of module autonomy? I propose that this separation is the very foundation of autonomy. By isolating our domain logic, the first benefit we receive is clarity. With this clarity we are able to focus all of our creative energy on the domain. Meanwhile, we can strive to keep the accidental complexity as simple as possible. That is, not just “thin controllers,” but boring controllers (and the like).
The second benefit we receive is freedom: freedom from extraneous coupling. This makes the most sense when you consider that the UI is where our application “comes together.” Every view the user sees is going to display information from multiple sources within our application, and will offer the user the ability to issue commands to various components of the application. Add to this the fact that many UI objects are tightly coupled to each other (e.g., views and controllers), and it becomes clear that commingling UI objects with domain objects is an invitation for extraneous coupling.
The final benefit we receive is independence. In discussions of Clean/Hexagonal/Onion patterns, this is often framed as the freedom to “swap out” external dependencies–like ActiveRecord or even Rails itself. While this is technically true, I believe this view is looking in precisely the wrong direction. By separating accidental and essential complexity we enhance the maintainability, changeability, and even deletability of our domain logic. With a clear separation in place, we are able to reshape the internal (hidden) implementation of our domain logic at will–so long as we maintain the integrity of the outward facing interface. This is true independence.
By defining “what’s in, what’s out,” we establish the most important boundary in our application: the one that separates accidental complexity (UI, persistence, etc.) from essential complexity (domain logic). The clarity, freedom, and independence that this boundary provides is the cornerstone of the autonomy we seek for our modules.
Finding the Seams
If you’ve ever actually tried to implement the Clean/Hexagonal/Onion patterns (or even just looked at them closely), you may have come to the conclusion that they are incomplete. They do not fully solve the problem. Do we want just one container, one module, for all of our domain logic? No. The goal of modularity is to have more–perhaps many more–much smaller things. But how do we do that? How do we find the seams in our domain logic? The Clean/Hexagonal/Onion gurus have no answers–at least none that I have seen.
However, even in the absence of a comprehensive answer, there is still much to say about these “seams.” The first question is, what is the criteria for establishing a seam between modules that best protects their respective autonomy? Returning to the experience of David Parnas, we find an important lesson to be learned. When Parnas composed his modules based on the new criteria of “information hiding,” he found that his system was more resilient to change: that is, changes in system requirements necessitated changes to fewer modules–often only a single module. He clearly felt that this new approach to composition was an improvement.
“We propose . . . that one begins with a list of difficult design decisions or design decisions which are likely to change. Each module is then designed to hide such a decision from the others.”1
Stated another way: things that are likely to change together belong together. And the corollary: things that are not likely to change together belong apart.
While this is laudable advice, it appears there remains much art to finding the correct seams. There is certainly much lore grown up around it–and many, many books. The most well-known approach has to be Domain-Driven Design. DDD looks first to the language of the end users, the “domain experts,” to find seams. This approach has an intuitive appeal: the usage of different language for a concept is a strong indicator of different criteria for usage, and of different criteria for change.2
Further discussion on finding the seams between modules is beyond the scope of this article. Before we move on, however, let’s discuss two basic characteristics of our seams: what is allowed to cross, and in what direction. In the systems we are discussing (modular monoliths), what passes between modules are messages in the form of method calls. But each of these calls creates a contract between the caller and the receiver, and any future changes to this contract will require coordination between the two. To preserve autonomy, we would like to limit this coupling as much as possible.
Toward that end, I propose a second convention: to allow all calls from UI objects to public methods in the modules, and to focus only on managing dependencies between modules. In Packwerk terms, I am suggesting that controllers and other UI classes be removed from all Packs and kept in the app directory, just as in a conventional Rails app (using namespaces for further organization, if necessary), and that calls from these classes to the public methods of all Packs be ignored by Packwerk.
My logic for this proposal is that method calls from the UI classes pose no threat of creating cyclic dependencies, because no Packs should rely on the UI classes as a dependency. These calls from the UI are not only expected, they are the designed behavior of the system: the UI calls the domain logic, but the domain logic should never call the UI directly.
The value of these two conventions is that developers can use Packwerk tools to focus on the dependencies that matter most: dependencies between Packs. In a dream scenario, with all of the accidental complexity removed and accounted for, we might be able to eliminate all dependencies between Packs. But this may not be realistic in systems of even moderate size (unless, that is, we implement some kind of evented system . . . 🤔).
Finally, with regard to the objects passed into modules with these method calls, I propose a third convention: that only data, not behavioral objects, should cross the boundaries between modules. For me this usually means value objects, a Hash containing user input, and perhaps Structs (or Data objects) on the input side, and Dry-rb Result objects on the return side. Passing behavioral objects, including ActiveRecord objects, would compromise the autonomy of the module by creating a contract (coupling) between the current module and the module where the object originated.
With three conventions in place so far, let’s look at one final topic.
Beware the Monolithic Database
It’s worth discussing the monolithic database because it poses a problem for all monoliths, modular or not. The fact is that existing tables tend to attract new fields in the same way that God Object classes attract new code. If there is some new attribute that involves users, it’s probably going to be added to the Users table (and class) without further thought. This is often a failure of both database design and system architecture.
The monolithic database is an obstacle to modularization because of the likelihood that two modules will want to own different attributes (fields) from the same table. If both modules share the table, a pernicious stealth coupling is created, where the modules are tied together through the database rather than through code. From the perspective of autonomy, this is a distinction without a difference: the autonomy of both modules is impaired. Neither module can change without coordinating with the other. Changes will be more difficult to make.
To preserve the autonomy of the modules, the monolithic database is eliminated by decomposing tables along with the modules, with each module claiming authority over the attributes it “owns.” This points to a fourth convention: that modules should avoid stealth coupling through shared system dependencies. This is most obvious with shared databases, but applies equally to other dependencies that bind modules together when the need for change arises.
Wrap Up: Modularize Only if You Require the Affordances Modularization Provides
One of the podcasts I listen to consists of two software engineers that review an industry-related book each week. I saw recently that they had on their list 99 Bottles of OOP, by Sandi Metz, Katrina Owen, and TJ Stankus. I was looking forward to this episode, but was disappointed when it finally came up in my queue: both hosts declared that they “didn’t like” the advice given–and they had both decided not to even finish the book. 🫤 On reflection, I realized that neither of the hosts practices or is interested in object-oriented programming. Why then, I wondered, did they even bother to read this book?
This reminded me of a critical passage from the first chapter of 99 Bottles on the affordances of object-oriented programming:
Where you once optimized code for understandability, you now focus on its changeability. Your code is less concrete but more abstract—you’ve made it initially harder to understand in hopes that it will ultimately be easier to maintain. This is the basic promise of Object-Oriented Design (OOD): that if you’re willing to accept increases in the complexity of your code along some dimensions, you’ll be rewarded with decreases in complexity along others. OOD doesn’t claim to be free; it merely asserts that its benefits outweigh its costs.
I wish the podcasters had addressed this passage in their discussion: if they never accepted this premise, why would they ever be interested in the practices discussed in the book? I feel precisely the same way about modularization. If you have never felt the pain that modularization is intended to address, you are probably not interested in introducing modularity in your project.
But if you do feel this pain, then the affordances that modularity provides can help you–if you are willing to accept their cost. And that’s the rub: the stakeholders must all agree that the cost exacted by modularity is worth it. I believe it is, or I wouldn’t be writing this, and I think you do too, dear reader.
At the start of this article we set three goals for any good solution to the problem of growing system complexity. I believe that modularity satisfies all of them.
-
Modularity manages the ever increasing complexity of real-world interactions through the power of abstraction: that is, by encapsulating the complexity into discrete, digestible chunks.
-
Modularity tames the unrestrained proliferation of connections in a system by prescribing limited, explicit interfaces for interacting with modules.
-
Modularity cultivates and supports shared mental models through abstractions: these abstractions provide both an clearer high-level overview of the system, and the ability to understand individual modules in detail.
I don’t think that it’s much of a leap to say that autonomy should be the guiding principle of module design (it’s hardly an original thought), but the conventions I propose are open to debate:
- Modules should contain only domain logic (no UI objects).
- Only coupling between modules (not between the UI and modules) should be scrutinized and regulated (this doesn’t mean abandoning prescribed interfaces).
- Only data objects should be passed to and from modules (no behavioral objects).
- Modules must own their own data (and similar dependencies).
What do you think? Consider these conventions a starting point for conversation: if not these, then what?
Thank you for reading. Discussion, feedback, and corrections are welcome on Mastodon.
-
Parnas, DL. On the Criteria To Be Used in Decomposing Systems Into Modules, Carnegie-Mellon University, August, 1971. ↩
-
Another, purportedly more mathematical, approach is “residuality theory,” created by Barry O’Reilly. There are a few of his talks on residuality theory up on YouTube (like this one, for example). O’Reilly’s approach sounds intriguing but, as with the other architecture gurus (consultants! 🫤), frustratingly vague. I bought his book–well played, sir!–but I haven’t read it yet. ↩