
Complexity is the Thing

No dogma, just what I'm learning and thinking about right now.
Comments and feedback are welcome on Mastodon.
"If you're thinking without writing, then you just think you're thinking."
—Leslie Lamport
I recently caught Eileen Uchitelle’s RailsWorld 2024 talk, “The Myth of the Modular Monolith.” The talk reflected on Shopify’s effort to “modularize” their monolith using Packwerk, a static analysis tool they created for this purpose. Eileen’s talk followed an earlier article from the Shopify blog, “A Packwerk Retrospective,” that outlined the authors’ experience with implementing modularity patterns with Packwerk.
The purpose of this article is not to rehash these discussions. However, a thought that kept occurring to me while reading and watching them is the lack of agreement on some basic concepts:
-
What is the problem that they are trying to solve?
These are the questions I would like to explore in an effort to achieve some consensus around the issues and, hopefully, around solution patterns as well. This article will discuss the first question, with articles to follow for the remaining two.
A Brief History of Large Rails Apps
I’d be willing to bet that every RailsConf ever held has included at least one talk about “managing large Rails apps” or “what to do when your Rails app gets too big.” The advice presented in these talks tends to fall into a few broad categories.
-
Lean-In to Rails. This advice boils down to: just Rails harder. Use fat models, skinny controllers, namespaces, and concerns, etc. The problem with this advice is that it doesn’t go far enough, and it refuses to accept the possibility that these tactics might be insufficient to tame all Rails apps–despite much evidence that this is so.
-
More Layers. This advice zigs precisely where the previous advice zags: MVC is not enough; more layers are needed. The implementation details in this category vary widely, but usually center around adding a “service layer” to “move the business logic out of Rails.” The value of this advice is a hugely contentious topic in the Rails community, but I would argue simply that it does not do enough to address the root issue.
-
Be Better. This advice is, in my mind, the most pernicious. It centers around the idea that the friction found in large Rails apps is caused by the developers themselves. You can identify this category through its use of vague, ephemeral, or tautological metaphors like “cruft” and “tech debt.” The prescriptions in this category are similarly incoherent: the team just needs more “discipline” or we just need to improve our “culture.” While code quality is an important goal, I believe this argument goes too far. In my mind, this category boils down to one thing: shame-driven development. It is not only unhelpful, but counterproductive–destructive even. I refuse to give any oxygen to this particular argument.
-
More, Smaller Things. The centerpiece of this advice is Ye Olde Nuclear Option: microservices. If working on your giant app is too hard, just blow it up! 👷🧨 However, this category includes other, less drastic options like Component-Based Rails Apps (CBRA) and Packwerk “packs.” The basic premise of these options is that more, smaller Rails apps are preferable to one large one.
Broadly speaking, this last category is consistent with the modular approach I want to discuss here. The problem with the specific solutions mentioned above is that some can be overkill (e.g., microservices) or functionally impractical (e.g., CBRA)–and all lack meaningful guidance on their goals and implementation.
The goal of this series of articles is to fill in some of those missing details and establish a common vocabulary around modularity and what it’s trying to accomplish.
So What is the Problem?
The art of programming is the art of organizing complexity, of mastering multitude and avoiding its bastard chaos.
–Edsger Dijkstra, Notes on Structured Programming
No sense beating around the bush: complexity is the problem that modularity is trying to solve. But what exactly does this mean? I believe that any program designed to address a problem in the real world is doomed to creeping, inevitable, relentlessly increasing complexity. There is much evidence to support this view.
Lehman’s Laws of Software Evolution
In the mid-1970s, Meir “Manny” Lehman, a researcher at IBM, began formulating what would become known as “Lehman’s Laws of Software Evolution.” As a basis for these laws, Lehman stated that programs could be divided into two categories1: S-programs and E-programs. S-programs can be completely specified, and the validity of their function determined solely by reference to their specifications. A good example of an S-program is a simple arithmetic calculator.
E-programs, on the other hand, are programs designed to “solve a problem or address an application in the real world.” Although E-programs can be defined through specifications, their validity must ultimately be judged by their utility in the real world. For example, a weather prediction system may meet its specifications, but its validity will be determined by how well its forecast matches the weather outside. The validity of E-systems rests on “human assessment of [their] effectiveness in the intended application”: a program might be “correct” but useless, or incorrect in one or more specifications but actually useful.
More importantly for our discussion, because of their convergence with the real world, E-type systems exhibit a “bias towards complexity.” Indeed, the eight “laws” that Lehman eventually defined are focused on the ways in which the “real world” forces a relentless march towards increased complexity in E-systems over time. This makes sense. Even if we start with the leanest of MVPs, with every feature that we add, and every edge case that we find and handle, our application swallows another chunk of the real world, and its complexity increases.
Metcalfe’s Curse
In many ways, this increase in complexity can be directly related to the growing size of the application. Consider Metcalfe’s Law. Robert Metcalfe, a co-inventor of ethernet technology, observed:
The financial value or influence of a telecommunications network is proportional to the square of the number of connected users of the system.
Metcalfe’s argument was that if the value of an ethernet device is determined by the number of connections it can make, then the value of each individual device grows exponentially as the network grows. This is an example of the “network effect,” illustrated below.
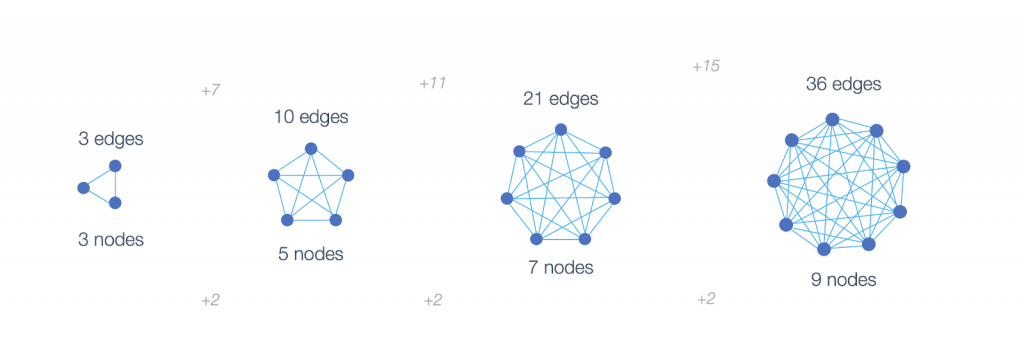
In this model, the value of each node increases with the number of connections it is able to make. But what if, instead of phones or ethernet devices, each of the nodes in this diagram were objects in our application–a controller or view, a function or an ActiveRecord class, or what have you? Suddenly the exponential proliferation of communication pathways becomes a measure of the potential chaos in our system.
This is the inverse network effect: with every new node, the complexity of our system increases at an exponential rate. When each object in our system can talk to any other, Metcalfe’s Law becomes Metcalfe’s Curse. As the system grows, it becomes harder and harder to understand–and harder to change–regardless of the quality of the code! Look at the last diagram above and picture it with hundreds or thousands of nodes representing the number of objects in your application. The image you see in your head is a Circular Firing Squad of Combinatorial Chaos.
Shared Mental Models
The increase in complexity in growing systems can also be directly related to growing team size. This is due to the difficulty of creating and maintaining shared mental models. This problem is humorously illustrated in the Tree Swing Project cartoon, which has been around in some form for over fifty years.
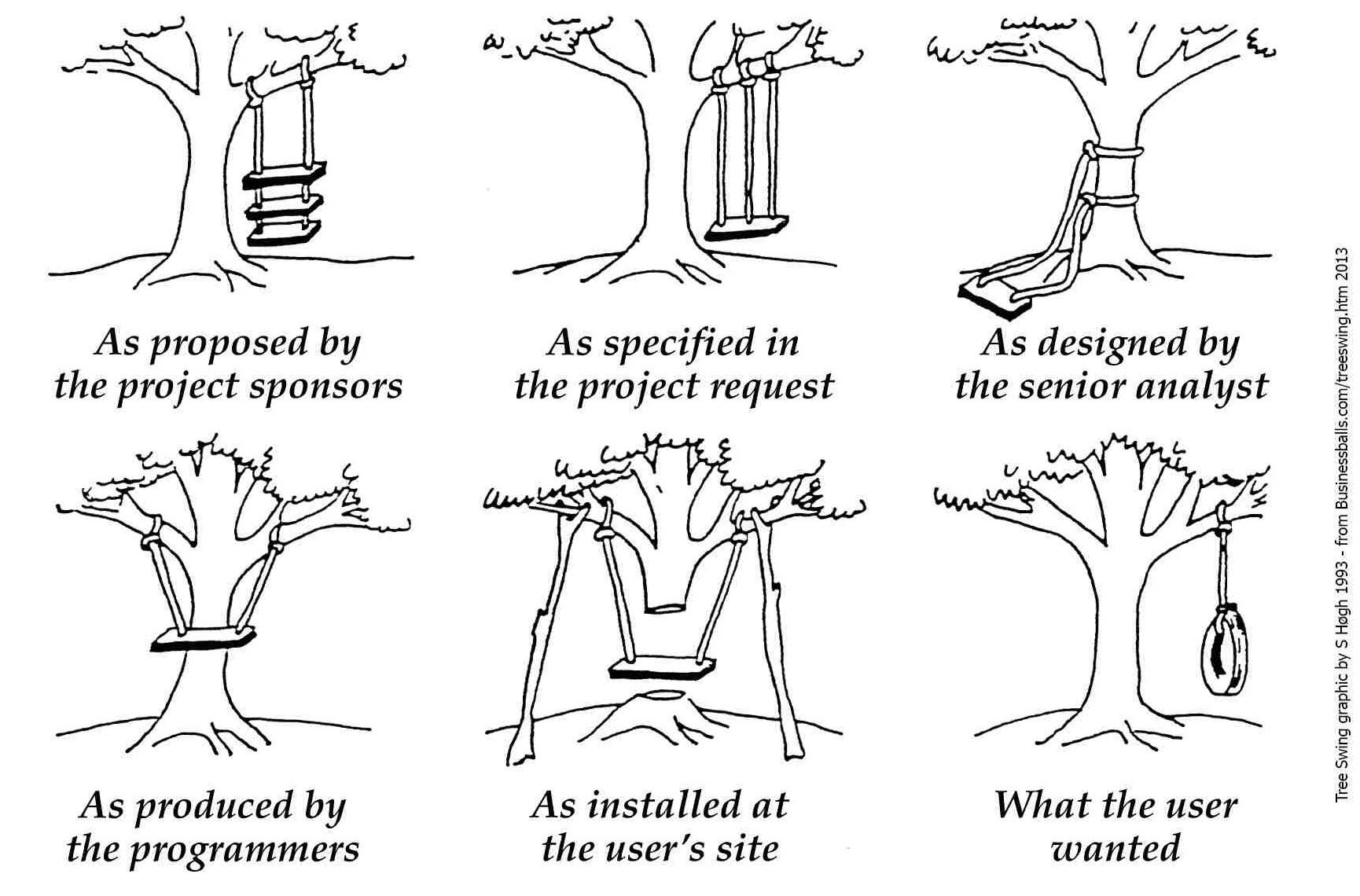
The point of the cartoon is that mental models dictate outcomes. This makes it critical that team members–and stakeholders–all share the same mental model of the application. This is a difficult task. The same sentiment has been expressed by many different people, but my favorite quote is from Alberto Brandolini:
It’s developers’ (mis)understanding, not expert knowledge that gets released in production.
How does this apply to our current topic? Sustained effort is required to maintain a shared mental model. With every feature added, the mental model gains a new facet that must be disseminated among and assimilated by team members. Likewise, the burden on new team members to absorb the shared mental model and “get up to speed” also increases.
As the application grows–and the team cultivating it grows–the effort involved to maintain the shared mental model of the complete system becomes unsustainable. At this point onboarding new developers becomes a long and difficult process, and the shared mental model begins to breakdown: cliques begin to form and specialists start to emerge for different parts of the system.
This brings us to Conway’s Law2:
[O]rganizations which design systems . . . are constrained to produce designs which are copies of the communication structures of these organizations.
If we substitute “mental models” for “communication structures,” we can see how this maxim reflects our current discussion.
Conway’s Law is well-known enough that I don’t need to belabor it here. However, I would like to share the observation that Conway’s Law is not really a strategy nor a prescription; it is a statement of fundamental human behavior–and a warning. Organizations that disregard it do so at their own peril–and to their detriment.
Where Do We Go From Here?
If my premise is right, it looks like we need a solution that:
-
Allows for the increasing complexity caused by real-world interactions.
-
Manages the proliferation of connections in a system destined to grow over time.
-
Cultivates sustainable shared mental models.
In the next article we’ll see if modularity fits the bill.
Thank you for reading! Discussion, feedback, and corrections are welcome on Mastodon.
-
In the original paper, Lehman actually defined three categories: S, P, and E-types. But he then grouped P and E types together as “A-types” for purposes of the Laws (A for “real-world applications”). In later papers he seems to use “E-type” to mean the same thing as A-type. Forgive me for glossing over this unnecessary complexity. ;-) ↩
-
“How do Committees Invent?” Datamation, April 1968. ↩