UPSERTing with ROM and Sequel

No dogma, just what I'm learning and thinking about right now.
Comments and feedback are welcome on Mastodon.
"If you're thinking without writing, then you just think you're thinking."
—Leslie Lamport
The Problem
Imagine that you have a parent entity, say a baseball Team, that has-many Players. I want to have an edit page for the Team that includes the Players on the Team. On the edit page, I want to be able to edit the Team info, the individual Player info, and add or remove players as needed.
Now the ideal solution, I suppose, would be to place multiple forms on the page for every Team and Player entity, and maybe use Javascript to automatically submit forms and handle adding and deleting players. That would be cool, but I’m still in MVP Land, so my plan was just to render one Team edit form, with the Players listed as a collection within the form. The form would then update all of the records on submit. I still need a little JS to add and delete players, but I’ll discuss how I handled that in another post.
To be clear, this process requires two database updates: one for the Team and one for the Players collection. Updating the Team is straightforward, but I wondered if I could update the Players collection in a single call to the database. 🤔
Is UPSERT a Solution?
Somewhere in the recesses of my brain I had the idea of an UPSERT concept in SQL. In my UPSERT fantasy land, I would just pass in a collection of existing and new Players, whatever the case may be, and UPSERT would sort out the new records, persist them, and persist any changes to existing records. Magic! Just what I need!
Now to DuckDuckGo Postgres UPSERT . . .
Postgres INSERT … ON CONFLICT
I’ll save you the trouble. It doesn’t exist.
That is, there is no UPSERT command in Postgres. However, since Postgres 9.5, there is an ON CONFLICT DO clause supported in INSERT statements that more or less does what we want.
Let’s examine that more-or-less qualifier. Here are the Postgres docs for ON CONFLICT:
The optional
ON CONFLICTclause specifies an alternative action to raising a unique violation or exclusion constraint violation error. For each individual row proposed for insertion, either the insertion proceeds, or, if an arbiter constraint or index specified by conflict_target is violated, the alternative conflict_action is taken.ON CONFLICT DO NOTHINGsimply avoids inserting a row as its alternative action.ON CONFLICT DO UPDATEupdates the existing row that conflicts with the row proposed for insertion as its alternative action.
It looks like ON CONFLICT provides us with an alternate path for behavior where a normal INSERT would cause some kind of constraint violation. Based on the above, it looks like what we need to perform an UPSERT-like operation is ON CONFLICT DO UPDATE. Let’s look at the example from the docs.
INSERT INTO
distributors (did, dname)
VALUES
(5, 'Gizmo Transglobal'),
(6, 'Associated Computing, Inc')
ON CONFLICT (did) DO
UPDATE
SET
dname = EXCLUDED.dname;
Here we can see that we need to provide ON CONFLICT with the name of the field that may violate constraints, then we provide an UPDATE clause containing the alternate behavior that we want to see if there is a conflict. In this case, the potential conflict field is did, and the alternate behavior is to update the dname field instead of creating a new record.
Note the special EXCLUDED table that is used by Postgres to store the “excluded” values for an individual record that can’t be inserted due to a conflict or constraint violation. We must reference this table to retrieve these values for use in the UPDATE clause.
Now I know this looks tantalizingly close to our desired behavior, but there are some subtleties here that are about to make our work a bit more difficult. Stay tuned . . .
The Shape of Our Data
Let’s take a step back for a moment and look at the shape of our data. We’re working with an HTML form that will be submitted over HTTP as a POST request. I’m using Hanami, which relies on Rack to handle HTTP requests and parse request bodies. I imagine that after all that handling, my app might receive form data that looks something like this.
{"team"=>
{"id"=>"13",
"name"=>"Bad News Bears",
"players"=>
[{"id"=>"1", "name"=>"Amanda Whurlitzer", "position"=>"Pitcher"},
{"id"=>"2", "name"=>"Tanner Boyle", "position"=>"Short Stop"},
{"id"=>"", "name"=>"Ahmad Abdul-Rahim", "position"=>"Center Field"}]}}
We see here that the Team entity contains only an id and a name, while the Player entities contain an id, a name, and a position. The data is shaped this way due to the choices I made in crafting my HTML form. For example, I chose not to include a team_id in the Player attributes because I can read it from the Team entity. In the case of a new team, since I persist the Team record first I can retrieve the new Team id and reference it when saving the Players. Likewise, I chose to represent new players (see Ahmad Abdul-Rahim in the example) with an empty id value. Others may choose to omit the id attribute altogether in the HTML form for new Player records.
The point is, however you choose to shape your data for the HTML/HTTP/application round-trip, we must then consider how to reshape it to satisfy Postgres. Let’s look at that process next.
Upserting Our Data to Postgres
Let’s start by assuming that our data has been converted from HTTP strings to native Ruby data types. In this case, that just means converting the various ids to integers. For the one new Player record, we will convert the empty id to nil. With that, let’s see what it might look like to plug our data into the SQL example from above. Note that Sequel will convert our Ruby nil values to NULL in SQL.
INSERT INTO
players (team_id, id, name, position)
VALUES
(13, 1, 'Amanda Whurlitzer', 'Pitcher'),
(13, 2, 'Tanner Boyle', 'Short Stop'),
(13, NULL, 'Ahmad Abdul-Rahim', 'Center Field')
ON CONFLICT (id) DO
UPDATE
SET
name = EXCLUDED.name,
position = EXCLUDED.position;
Now, you might be as surprised as I was to learn that this does not work. The new Player record raises an exception because Player id cannot be NULL. In ROM, just as in ActiveRecord, we typically leave the id blank when creating new records and let the database supply a value, usually from an auto-incremented series. You might think, then, that the way to go here is to leave the id value blank in the new Player record, but that doesn’t work either. This is because SQL, unlike Ruby, is strictly typed. Let’s look at what SQL actually expects in this situation.
INSERT INTO
players (team_id, id, name, position) # Note ❶
VALUES
(13, 1, 'Amanda Whurlitzer', 'Pitcher'), # Note ❷
(13, 2, 'Tanner Boyle', 'Short Stop'),
(13, SOME_VALUE, 'Ahmad Abdul-Rahim', 'Center Field') # Note ❸
ON CONFLICT (id) DO
UPDATE
SET
name = EXCLUDED.name,
position = EXCLUDED.position;
Notes:
-
We must tell SQL up-front what columns will be included in the
VALUESblock. -
Each array of values must provide a value for every column listed above, regardless of whether the array represents a new or updated record. The values in each array must match the order and column type of the columns in the list. Each value must also conform to any additional constraints that might exist on the respective column.
-
We must provide a value for
idin new records. This value must be of the correct type for this column, and must not conflict with an existing record.
As you can see, there are two main problems here: each array in our value list must have the same number of elements and, therefore, we must supply some value for the id field of each new record. This last bit is what really let all of the air out of my UPSERT balloon.
How am I supposed to know what id value to supply in the SQL statement for new records? And how will I provide that value when working in ROM? If my id were a UUID, I could just generate the UUID in Ruby and add it to any new records before persisting. But most id fields tend to be of the auto-incrementing integer variety and are managed internally by the database. How can we account for that in our current scenario? Let’s look at a couple of solutions that I found.
Accessing the id Sequence Directly
The first solution I found is to ask Postgres to supply an id value by directly referencing the Postgres sequence underlying this column. Sequences are generators that supply values for auto-incrementing fields. Although sequences are created for you automatically and live mostly behind the scenes, they are named in a predictable way and have functions available to access and manipulate them. Therefore, we can use the Postgres sequence underlying our Players id column to provide values for our new records. For example, to get the next value for our Players id, we could use the Postgres nextval function: nextval('players_id_seq').
Let’s see what that would look like in our full example.
INSERT INTO
players (team_id, id, name, position)
VALUES
(13, 1, 'Amanda Whurlitzer', 'Pitcher'),
(13, 2, 'Tanner Boyle', 'Short Stop'),
(13, nextval('players_id_seq'), 'Ahmad Abdul-Rahim', 'Center Field')
ON CONFLICT (id) DO
UPDATE
SET
name = EXCLUDED.name,
position = EXCLUDED.position;
This works. FINALLY! HOORAY!
Now, we’ve been looking at a lot of SQL so far. Let’s celebrate our victory by translating this code to Ruby using Sequel.
I want to give a big shout-out here to Jeremy Evans, the lead maintainer of the Sequel gem and many others. You would be hard pressed to find a more dedicated, productive, or responsive maintainer anywhere in the software industry. I posted a question on this topic to Sequel’s Github Discussions page late one weeknight. Amazingly, Jeremy responded personally in about thirty minutes. I am in no way suggesting that this should be the norm for project maintainers, but I want to thank Jeremy for being an incredible maintainer himself. He has also written a great book, Polished Ruby Programming. I bought it and you should too! 🤓
To perform our insert-on-conflict with Sequel, we will need to provide our on-conflict options to the insert_conflict method, and supply our data using a chained multi_insert method. This could look something like this.
conflict_options = {
target: :id,
update: {
name: Sequel[:excluded][:name],
position: Sequel[:excluded][:position]
}
}
player_list = [
{team_id: 13, id: 1, name: "Amanda Whurlitzer", position: "Pitcher"},
{team_id: 13, id: 2, name: "Tanner Boyle", position: "Short Stop"},
{team_id: 13, id: Sequel.function(:nextval, "players_id_seq"), name: "Ahmad Abdul-Rahim", position: "Center Field"}
]
DB[:players]
.insert_conflict(conflict_options)
.multi_insert(player_list)
This works just fine, but is not ideal. In order to use this approach, we need to know the name of the sequence ahead of time. This feels tightly coupled and difficult to maintain. We could reduce the coupling by using a specialized Postgres introspection function to find the sequence name based on the known table and column names: nextval(pg_get_serial_sequence('players', 'id'));. But this still feels too tightly coupled to Postgres internals. I would prefer a more generalized approach. Let’s keep looking.
The DEFAULT Keyword
After some searching, I found this Stack Overflow response suggesting the use of the DEFAULT keyword in place of missing ids for new records. Incorporating this simple change brings our SQL to this.
INSERT INTO
players (team_id, id, name, position)
VALUES
(13, 1, 'Amanda Whurlitzer', 'Pitcher'),
(13, 2, 'Tanner Boyle', 'Short Stop'),
(13, DEFAULT, 'Ahmad Abdul-Rahim', 'Center Field')
ON CONFLICT (id) DO
UPDATE
SET
name = EXCLUDED.name,
position = EXCLUDED.position;
And translating this to Ruby with Sequel could look something like this.
conflict_options = {
target: :id,
update: {
name: Sequel[:excluded][:name],
position: Sequel[:excluded][:position]
}
}
player_list = [
{team_id: 13, id: 1, name: "Amanda Whurlitzer", position: "Pitcher"},
{team_id: 13, id: 2, name: "Tanner Boyle", position: "Short Stop"},
{team_id: 13, id: Sequel.lit("DEFAULT"), name: "Ahmad Abdul-Rahim", position: "Center Field"}
]
DB[:players]
.insert_conflict(conflict_options)
.multi_insert(player_list)
Success!
Bringing it Back to ROM
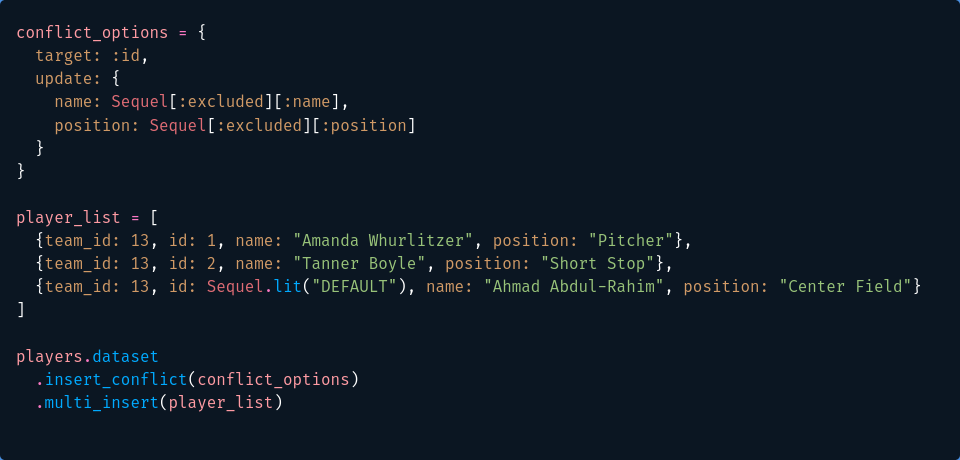
In my Hanami app, I then had to implement this logic in my ROM repository. The idiomatic way to implement upsert in ROM is to write a custom Command class, register the Command, and call it from your repository. In my case, still working in MVP Land, I wanted a simpler solution. So I used the ROM dataset method to “drop down” to Sequel and used the Sequel methods from there right in my repository class. My final solution looked something like this.
conflict_options = {
target: :id,
update: {
name: Sequel[:excluded][:name],
position: Sequel[:excluded][:position]
}
}
player_list = [
{team_id: 13, id: 1, name: "Amanda Whurlitzer", position: "Pitcher"},
{team_id: 13, id: 2, name: "Tanner Boyle", position: "Short Stop"},
{team_id: 13, id: Sequel.lit("DEFAULT"), name: "Ahmad Abdul-Rahim", position: "Center Field"}
]
players.dataset
.insert_conflict(conflict_options)
.multi_insert(player_list)
Wrapping Up
If you prefer to implement upsert as a ROM Command, I recommend following this excellent guide and incorporating the additional strategies outlined here. For extra credit, I also invite you to learn about the MERGE command in Postgres, and how it compares to insert-on-conflict.
Good luck! Thank you for reading!